Manejo de vectores y matrices en Python: Módulo NumPy Parte 2#
![]()
import os
import matplotlib.cm as cm
# Módulos para representación gráfica en 3D
import matplotlib.pyplot as plt
# Creando matriz de prueba A
import numpy as np
# Módulo para análisis simbólico
# (En este código se utiliza para representar las matrices)
import sympy as sy
# Ploteo de soluciones
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
# Matrices sparse
# Módulo de scipy que permite trabajo con matrices sparse
from scipy.sparse import spdiags
from scipy.sparse.linalg import spsolve
Generando Matrices#
Las matrices en Python numérico pueden ser representadas de varias formas.
Una de ellas es mediante el uso de vectores 2-dimensionales o 2darray.
Más adelante se mostrará otra estructura de dato para representarlas.
Seguidamente se brindan algunos ejemplos de cómo generar matrices con vectores bidimensionales.
Generar la matriz identidad
ident = np.identity(4)
print("El tipo es:", type(ident))
print(ident)
El tipo es: <class 'numpy.ndarray'>
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
Generando matrices que poseen \(1\)’s en una de sus diagonales.
El parámetro k representa la posición de la diagonal seleccionada.
uno_sup = np.eye(10, k=1) # Seleccionar la diagonal superior a la diagonal principal
print("Diagonal superior:\n", uno_sup)
uno_inf = np.eye(10, k=-1) # Seleccionar la diagonal inferior a la diagonal principal
print("Diagonal inferior:\n", uno_inf)
Diagonal superior:
[[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
Diagonal inferior:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]]
Una forma más general de generar una matriz diagonal es usando la función np.diag.
Esta permite especificar cada uno de los elementos de la diagonal y su posición con respecto a la diagonal principal con el parámetro k.
diag = np.diag(np.array([1, 4, 1, 4, 1, 4, 1, 4]), k=1)
print(diag)
[[0 1 0 0 0 0 0 0 0]
[0 0 4 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0]
[0 0 0 0 4 0 0 0 0]
[0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 4 0 0]
[0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 4]
[0 0 0 0 0 0 0 0 0]]
El proceso inverso es también posible, obtener un vector con los valores de una diagonal de la matriz considerando su desplazamiento.
print(np.diagonal(diag, offset=1))
[1 4 1 4 1 4 1 4]
Otras funciones útiles ya se encuentran diseñadas en la biblioteca NumPy para obtener información de los elementos de una matriz evitando ciclos explícitos en Python.
m = np.array(
[
[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45],
[51, 52, 53, 54, 55],
]
)
print("Matriz_ej:\n", m)
Matriz_ej:
[[11 12 13 14 15]
[21 22 23 24 25]
[31 32 33 34 35]
[41 42 43 44 45]
[51 52 53 54 55]]
Un ejemplo de ello es la traza de la matriz la cual suma los elementos de la diagonal.
print("Suma de la diagonal principal:", m.trace())
Suma de la diagonal principal: 165
También se pueden citar otros dos ejemplos, triu y tril.
La primera devuelve la correspondiente matriz triangular superior.
La segunda devuelve la correspondiente matriz triangular inferior.
np.triu(m)
array([[11, 12, 13, 14, 15],
[ 0, 22, 23, 24, 25],
[ 0, 0, 33, 34, 35],
[ 0, 0, 0, 44, 45],
[ 0, 0, 0, 0, 55]])
np.tril(m)
array([[11, 0, 0, 0, 0],
[21, 22, 0, 0, 0],
[31, 32, 33, 0, 0],
[41, 42, 43, 44, 0],
[51, 52, 53, 54, 55]])
Vistas de vectores#
Al realizar una selección en un vector el resultado no se almacena en un nuevo vector directamente, sino que se crea una vista del vector. Esto significa que en la memoria los elementos de la nueva selección son exactamente los elementos seleccionados del vector y no se ocupa memoria adicional. Por tal motivo, si se modifica alguno de ellos en una vista entonces se modificarán en el propio vector también. En otras palabras, la vista es una estructura lógica que contiene una configuración diferente de los elementos del vector al que apunta. Por ejemplo:
Creemos una matriz usando un listado de números y la operación np.reshape la cual
realiza un cambio de tamaño de las dimensiones de los elementos
(esta función será explicada más adelante).
# La secuencia [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25]
# es reconfigurada en una matriz de 5 x 5 elementos.
A = np.arange(1, 26, 1).reshape((5, 5))
A
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
Realicemos una selección de la submatriz (vista) comprendida entre \(1\leq i\leq 3\) y \(1\leq j\leq 3\):
B = A[1:4, 1:4]
B
array([[ 7, 8, 9],
[12, 13, 14],
[17, 18, 19]])
Asignemos el valor \(0\) a cada elemento de la vista \(B\).
B[:, :] = 0
B
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
Entonces la matriz \(A\) tendrá los \(0\)’s en los valores seleccionados por la vista.
A
array([[ 1, 2, 3, 4, 5],
[ 6, 0, 0, 0, 10],
[11, 0, 0, 0, 15],
[16, 0, 0, 0, 20],
[21, 22, 23, 24, 25]])
¿Cuál es la diferencia entre escribir B[:, :] = 0 y B=0?
# B = 0
print("B:", B)
print("Tipo de B:", type(B))
print("A:", A)
B: [[0 0 0]
[0 0 0]
[0 0 0]]
Tipo de B: <class 'numpy.ndarray'>
A: [[ 1 2 3 4 5]
[ 6 0 0 0 10]
[11 0 0 0 15]
[16 0 0 0 20]
[21 22 23 24 25]]
Ahora, cómo se puede crear una nueva matriz a partir de la vista resultado de una selección.
C = np.copy(B)
C
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
Comprobando volvemos a crear la matriz A y ejecutamos nuevamente la vista. Luego asignamos a la vista B el valor 0.
A = np.arange(1, 26, 1).reshape((5, 5))
B = A[1:4, 1:4]
B[:, :] = 0
print("A:\n", A)
print("B:\n", B)
print("C:\n", C)
A:
[[ 1 2 3 4 5]
[ 6 0 0 0 10]
[11 0 0 0 15]
[16 0 0 0 20]
[21 22 23 24 25]]
B:
[[0 0 0]
[0 0 0]
[0 0 0]]
C:
[[0 0 0]
[0 0 0]
[0 0 0]]
¿Si quisiera volver a restaurar los datos anulados de \(A\) utilizando la información de \(C\) qué podría hacer?
A[1:4, 1:4] = C[:, :]
A
array([[ 1, 2, 3, 4, 5],
[ 6, 0, 0, 0, 10],
[11, 0, 0, 0, 15],
[16, 0, 0, 0, 20],
[21, 22, 23, 24, 25]])
¿La siguiente línea de código también funcionará de la misma manera? ¿Lanzará algún error?
A[1:4, 1:4] = C
A
array([[ 1, 2, 3, 4, 5],
[ 6, 0, 0, 0, 10],
[11, 0, 0, 0, 15],
[16, 0, 0, 0, 20],
[21, 22, 23, 24, 25]])
La operación de asignación = se ha redefinido en la biblioteca NumPy.
¿Qué pasaría si ahora se modifica uno de los valores de la matriz \(C\)?
C
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
C[2, 2] = 100
print("A:\n", A)
print("C:\n", C)
A:
[[ 1 2 3 4 5]
[ 6 0 0 0 10]
[11 0 0 0 15]
[16 0 0 0 20]
[21 22 23 24 25]]
C:
[[ 0 0 0]
[ 0 0 0]
[ 0 0 100]]
Indexación avanzada#
Hasta el momento la selección se ha ido realizando especificando números e intervalos en las expresiones de selección para cada una de las dimensiones, pero existen otras formas más avanzadas de seleccionar elementos las cuales mostraremos en esta sección.
Es posible realizar selección de índices previamente especificados en una secuencia (lista, tupla, vector, etc.). Veamos un ejemplo. Supongamos que se quieren seleccionar los elementos con los índices \(0\), \(2\) y \(4\) de un vector
vec = np.arange(1, 11, 1)
vec
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
El vector de índices de interés es
idx = np.array([0, 2, 4])
idx
array([0, 2, 4])
Luego la selección se realiza al pasar en el operador de selección [ ] la secuencia de índices
vec[idx]
array([1, 3, 5])
Lo mismo puede ser llevado a cabo con una lista
vec[[0, 2, 4]]
array([1, 3, 5])
Otra de las variantes de selección es la selección condicional. En este caso se puede establecer una condición booleana la cual es evaluada en cada uno de los elementos del vector, retornando un vector de valores booleanos con cada uno de los resultados de la evaluación en sus correspondientes índices.
Por ejemplo, supongamos que del vector vec quisiera saber cuáles son los elementos mayores que \(5\)
vec > 5
array([False, False, False, False, False, True, True, True, True,
True])
Ahora combinando con lo explicado en 146 se obtienen solo aquellos valores para los que la condición fue verdadera, aquellos mayores que 5.
vec[vec > 5]
array([ 6, 7, 8, 9, 10])
En este caso, es importante aclarar que la indexación avanzada NO es una vista. Al asignar el resultado de la indexación avanzada a una nueva variable esta creará un nuevo vector con su propio espacio reservado en memoria.
A = vec[vec > 5]
A[0] = -1
A[-1] = -1
print("A:\n", A)
print("vec:\n", vec)
A:
[-1 7 8 9 -1]
vec:
[ 1 2 3 4 5 6 7 8 9 10]
Pero a su vez es posible hacer cambios en el vector vec usando indexación avanzada.
Véase el siguiente ejemplo:
vec[[5, -1]] = -1
print("vec:\n", vec)
vec:
[ 1 2 3 4 5 -1 7 8 9 -1]
O también para indexación condicional:
vec[vec > 5] = -1
print("vec:\n", vec)
vec:
[ 1 2 3 4 5 -1 -1 -1 -1 -1]
Reconfiguración y redimensionalización de vectores#
Una situación muy usual cuando se trabaja con vectores y matrices es la reconfiguración de la disposición de sus elementos o la redimensionalización de sus dimensiones. Por ejemplo, un vector bidimenional de \(N\times N\) pudiera ser redimensionado en uno vector unidimensional de \(N^2\) o pudiera ser reconfigurado uniendo varios vectores o apilándolos vertical u horizontalmente. La biblioteca NumPy brinda un amplio listado de funciones para manipular vectores.
Resumen de funciones para manipular vectores
Función |
Descripción |
|---|---|
|
Redimensiona el array manteniendo la misma cantidad de elementos. Esto indica que \(i * j = n\). |
|
Crea un vector unidimensional a partir de un vector n-dimensional. Dicho de otra forma, la posición en el vector unidimensional del elemento |
|
Crea una vista unidimensional de un vector n-dimensional siempre que sea posible. De otra forma crea un nuevo vector. La indexación ocurre de igual forma que en |
|
Devuelve la transpuesta de un vector bidimensional. |
|
Apila (en la dimensión 1) una lista de vectores de forma horizontal, de izquierda a derecha. Devuelve una matriz con los mismos apilados |
|
Apila (en la dimensión 0) una lista de vectores de forma vertical, de arriba hacia abajo. |
|
Crea un nuevo vector que es la concatenación de un listado de vectores. *Es muy utilizado en conformación de matrices en PDEs solvers. |
|
Crea un nuevo vector como el original pero con dimensiones de tamaño diferente. Si el tamaño es mayor que el del vector original entonces los elementos sobrantes serán rellenados con los elementos del vector original siguiendo el mismo orden y comenzando desde el primero. *Esta también es muy útil en la conformación de matrices sobre todo en PDEs solvers de dimensión mayor que 1. |
|
Crea un nuevo vector con un elemento adicionado al final. Esta operación es computacionalmente costosa por lo que debe evitarse. |
|
Crea un nuevo vector con un elemento insertado en una posición determinada. Esta operación es computacionalmente costosa por lo que debe evitarse. |
|
Crea un nuevo vector eliminando uno de los elementos del vector original. Esta operación es computacionalmente costosa por lo que debe evitarse. |
Veamos algunos ejemplos del uso de estas funciones.
np.resize(B[:, 0], (B.shape[0] * A.shape[0], 1))
array([[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0]])
Vectorización de funciones y operadores#
El sentido de utilizar esta clase ndArray es poder utilizar las operaciones vectoriales
que ejecutan rutinas eficientes para los elementos del vector que están implementadas a
bajo nivel.
Por ejemplo, considérese la siguiente operación suma entre dos elementos:
def suma(x, y):
return x + y
Si se utiliza para sumar dos elementos funciona de acuerdo a lo esperado:
suma(2, 3)
5
Pero si se desea ejecutar sobre cada par correspondiente de elementos de una lista, entonces se esperaría que sume cada par de números correspondientes, uno de una y el otro de la otra. Pero el resultado no es el esperado:
a = [1, 2, 3]
b = [3, 2, 1]
suma(a, b)
[1, 2, 3, 3, 2, 1]
En efecto, las estructuras de datos utilizadas son listas por lo que la operación
+ está definida como una unión entre listas de elementos.
Veamos el ejemplo de una función que dada la comparación entre \(a\) y \(b\) decide sumarlos o restarlos. (Tomado de la documentación de NumPy)
def fun(a, b):
"Return a-b if a>b, otherwise return a+b"
if a > b:
return a - b
else:
return a + b
Este es un caso bien sencillo para el caso en el que no ha sido vectorizado:
print("1 < 4 =>", fun(1, 4))
print("4 > 2 =>", fun(4, 2))
1 < 4 => 5
4 > 2 => 2
¿Pero qué sucederá si se vectoriza esta función?
_fun = np.vectorize(fun)
Veamos el resultado del mismo ejemplo anterior pero esta vez con la versión vectorizada:
print("1 < 4 =>", _fun(1, 4))
print("4 > 2 =>", _fun(4, 2))
1 < 4 => 5
4 > 2 => 2
La función np.vectorize es una herramienta para «convertir» estas funciones
en expresiones que utilicen las ventajas de los ndarrays.
El resultado del ejemplo anterior es exactamente el mismo resultado obtenido para el caso no vectorizado, pero que pasa si extendemos los parámetros de entrada a secuencias de números:
a = [1, 2, 3, 4]
b = 2
_fun(a, b)
array([3, 4, 1, 2])
En este caso la operación definida en la función fue vectorizada y repetida por cada elemento de a.
¿Pero qué sucederá si también b es un listado de números (misma longitud que a)?
b = [2, 1, 0, 1]
_fun(a, b)
array([3, 1, 3, 3])
Efectivamente, se ejecutó la operación definida en fun para cada par correspondiente de elementos de a y b resultando en un nuevo array con el resultado de cada operación en su índice correspondiente:
Este es precisamente el concepto que se encuentra detrás de las operaciones vectorizadas que ya se encuentran implementadas en NumPy.
Entre ellas se encuentran las operaciones aritméticas entre los operandos a y b, vector-escalar y vector-vector:
Operators |
Description |
|---|---|
+, -, *, /, ** |
Operadores suma, resta, multiplicación división y potencia los cuales operan sobre cada par de operandos correspondientes de la forma \(c_{i}=a_{i}\) o \(b_{i}, i=0,1,\dots,len(c)\) (para la potencia sería \(c_{i} = {a_i}^{b_i}\)). |
Pero NumPy implementa una gran cantidad de funciones vectoriales. A continuación listo una selección resumen de las mismas:
función |
Description |
|---|---|
|
Funciones trigonométricas. |
|
Funciones trigonométricas inversas. |
|
Raíz cuadrada. |
|
Función exponencial. |
|
Función logaritmo de base \(e\), \(2\) y \(10\) respectivamente. |
|
Calcula el resto de la división entre dos arrays. |
|
Calcula el número recíproco de los números. |
|
Devuelve el signo del número (\(+, -\)). |
|
Calcula el valor absoluto de cada número. |
|
Devuelve el valor \(x_{floor} = \lfloor x\rfloor\). |
|
Devuelve el valor \(x_{ceil} = \lceil x \rceil\). |
|
Redondea por defecto el número de punto flotante a su entero más cercano de la siguiente manera: \(x = \begin{cases} \lfloor x \rfloor ,& \lfloor x \rfloor \geq x -\frac{1}{2} \\ \lceil x \rceil ,& \lfloor x \rfloor \le x -\frac{1}{2}\end{cases}\). |
|
Redondea un número de punto flotante a un cierto número de decimales. |
Ejemplo #1: Infiltración de Agua en el suelo.#
En este simple ejemplo se simulará la infiltración de agua en un acuífero confinado hipotético. El mismo fue diseñado de forma como un área cuadrada que representa un corte vertical lateral, impermeable en sus fronteras excepto la superior donde se define un flujo de agua entrante.
En la imagen se muestra una representación. Las líneas rojizas representan fronteras impermeables, la verde representa la frontera de intercambio y las flechas azules el flujo dentro de la grava.
Para modelar este problema se utilizará la Ley de Darcy que se expresa en la siguiente ecuación diferencial difusiva: \(S_{s}\dfrac{\partial u}{\partial t}=K\Delta u\), donde \(u\) representa la concentración de agua dentro del dominio, \(K\) es el coeficiente de conductividad hidráulica y \(S_{s}\) es el almacenamiento específico del acuífero en cuestión.
En este caso el espesor del acuífero \(\mu\) será fijado en \(1\) metro y el coeficiente de almacenamiento \(S=5e-5\) dado que es un suelo de gravilla. Entonces se tiene \(S_{s}=\frac{S}{\mu}\).
Luego, la conductividad hidráulica para ese tipo de suelo es \(K=1e-1\) \(m/\text{días}\) que llevándolo a segundos es \(K\approx 1.574e-6\) \(m/s\).
Replanteando la ecuación se obtiene que para el dominio \(\Omega=\left\{\left(x,y\right)\mid x, y \in (0, N_x)\times (0, N_y)\right\}\) y tiempo \(t\in\left[0, T\right)\) se cumple \(\dfrac{\partial u}{\partial t}-D\Delta u = 0\), siendo \(D=\frac{K \mu}{S}\) el coeficiente de difusión en \(m^2/s\).
Con respecto a las condiciones iniciales se considerará que no existe concentración de agua alguna en el dominio. De esta forma \(u\left(t=0, x, y\right)=0\), \(\forall x,y\in\Omega\).
Con respecto a las condiciones de frontera:
Fronteras impermeables: \(\dfrac{\partial u(t > 0, 0, y)}{\partial \vec{n}} = \dfrac{\partial u(t > 0, N_x, y)}{\partial \vec{n}} = \dfrac{\partial u(t > 0, x, 0)}{\partial \vec{n}} = 0, \, ∀ x \in [0, N_x], ∀ y \in [0, N_y]\)
Frontera de intercambio: \(\dfrac{\partial u(t > 0, x, N_y)}{\partial \vec{n}} = D(u(x, N_y) - g(t > 0, x)), \, ∀ x \in [1, N_x-1]\).
Note que las primeras tres definiciones se clasifican como condiciones de frontera de Neumann homogéneas. En el caso de la última, se clasifica como condición de frontera de Neumann, pero en este caso es heterogénea. O sea, se ha definido un flujo en la misma el cual tiene una tasa de intercambio definida por el coeficiente de difusión \(D\) y donde \(g\) representa el valor de la concentración en el exterior de la frontera.
Para resolver este problema numéricamente se utilizará un esquema de integración numérica explícito basado en diferencias finitas.
La discretización de las variables es como sigue:
Tiempo: \(t_{n}=n\Delta t, \, n=0, 1, \dots, T\)
Espacio: \(x_{j}=j\Delta x, \, y_k = k \Delta y : j = 0, 1, \dots N_x\) y \(k = 0, 1, \dots, N_y\)
En este caso por simplicidad asumiremos que \(\Delta x = \Delta y\) y \(N_x = N_y\).
Se representa la discretización de los operadores diferenciales en el siguiente esquema en diferencias:
\(\dfrac{u^{n+1}_{j\,k} - u^{n}_{j\,k}}{\Delta t}-D\dfrac{u^n_{j-1\,k}-2 u^n_{j\,k}+u^n_{j+1\,k}}{\Delta x^2} - D\dfrac{u^n_{j\,k-1} - 2 u^n_{j\,k} + u^n_{j\,k+1}}{\Delta y^2} = 0\).
Es importante destacar que este esquema explícito (uno de los más simples) para que brinde soluciones estables debe de cumplir la siguiente condición CFL (Courant-Friedrichs-Levy):
\(D\frac{\Delta t}{\Delta x^2} + D\frac{\Delta t}{\Delta y^2} ≤ \frac{1}{2}\)
lo cual para nuestro problema significa
\(2 D \frac{\Delta t}{\Delta x^2} = 2 r \le \frac{1}{2}\)
\(r \le \frac{1}{4}\).
Por tal razón se fijó \(r=0.2\) y \(\Delta x = 0.1\) y se calcula el valor de \(\Delta t\) de manera que sea estable la solución:
\(\Delta t = \frac{r \Delta x^2}{D}\).
Para el caso de las condiciones de frontera se utilizó una aproximación de segundo orden (esquema en diferencias centradas) para calcular la derivada con respecto al vector normal en cada uno de los casos de condiciones de Neumann homogéneas.
En este caso, en la ecuación resultante se hallará una variable que se encuentra fuera de \(\bar\Omega\). Para resolver este problema se asume que la ecuación de Laplace continúa siendo válida en la frontera (como de hecho lo es) y se elimina este término «indeseable».
Para el caso de la frontera con condiciones de Neumann heterogéneas, entonces se define el flujo y se sustituye en la ecuación de Laplace correspondiente dando lugar a un término no asociado a ninguna variable. Este será sumado al final de la operación.
El método puede finalmente plantearse de forma matricial de la siguiente manera: \(u^{n+1}=\left(A+R\right)u^{n}+r\).
El vector de soluciones \(u\) está definido para \(\bar{\Omega}\) de la siguiente manera:
\(u^n = \begin{bmatrix} u^n_{00} & u^n_{01} & \dots & u^n_{0N_y} & u^n_{10} & u^n_{11} & \dots & u^n_{1N_y} & \dots & u^n_{N_x0} & u^n_{N_x1} & \dots & u^n_{N_xN_y} \end{bmatrix}^T\).
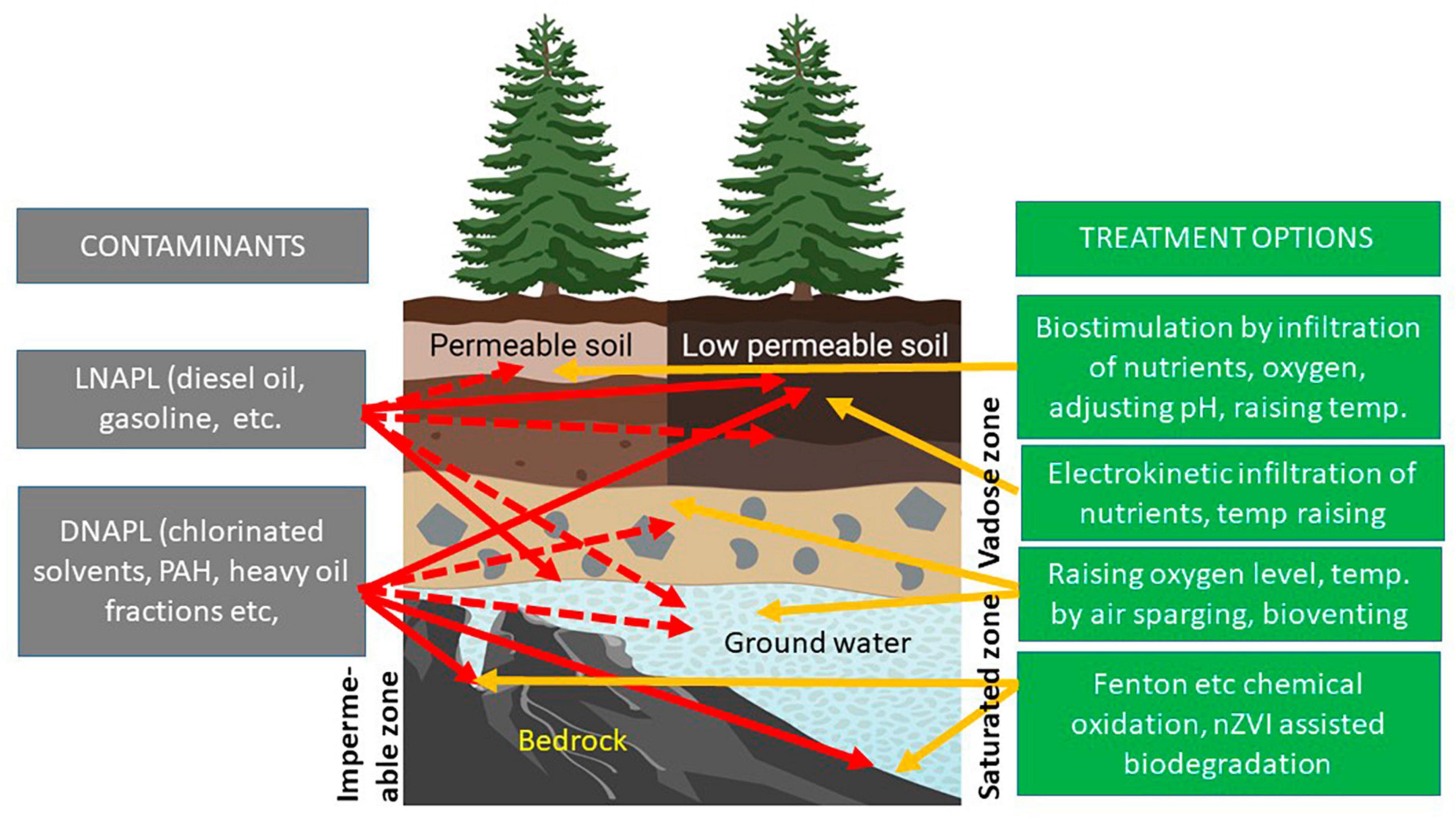
La matriz A es una matriz pentadiagonal de bloques. La misma se puede explicar de la siguiente forma:
\(A = \begin{bmatrix} B & 2 r I & 0 & & & \dots & 0 \\ rI & B & rI & 0 & & \dots & 0 \\ 0 & rI & B & rI & 0 & \dots & 0 \\ \vdots & \ddots & \ddots & \ddots & \ddots & \ddots & \vdots \\ 0 & \dots & 0 & rI & B & rI & 0 \\ 0 & \dots & & 0 & rI & B & rI \\ 0 & \dots & & & 0 & 2rI & B \end{bmatrix}\),
donde \(I\) es la matriz identidad y \(B\) es una matriz tridiagonal definida así
\(B = \begin{bmatrix} 1 - 4r & 2r & & & \\ r & 1 - 4r & r & & \\ & \ddots & \ddots & \ddots & \\ & & r & 1 - 4r & r \\ & & & 2r & 1 - 4r \end{bmatrix}\).
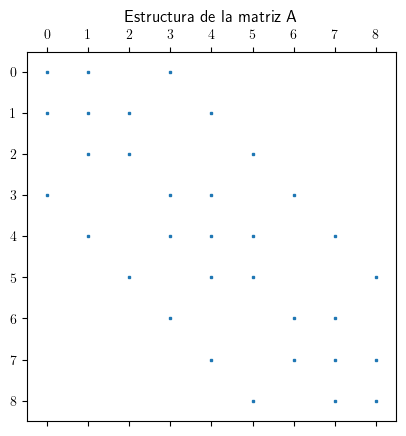
En el caso de la matriz R esta solo constará con el aporte que realiza la parte que calcula el flujo de intercamio asociada a las correspondientes variables \(u^n_{j\, N_y}\).
\(R = \begin{bmatrix} 0 & & & & & & \\ & \ddots & & & & & \\ & & 0 & & & & & \\ & & & 2r\Delta x D & & & & \\ & & & & 0 & & & \\ & & & & & \ddots & & \\ & & & & & & 0 & \\ & & & & & & & 2r\Delta x D \end{bmatrix}\)
Para el otro término relacionado con el flujo se construye el siguiente vector:
\(r = \begin{bmatrix} 0 \\ \vdots \\ 0 \\ 2 r \Delta x D g^n_1 \\ 0 \\ \vdots \\ 0 \\ 2 r \Delta x D g^n_2 \\ 0 \\ \vdots \\ 0 \\ 2 r \Delta x D g^n_{N_x - 1} \\ 0 \\ \vdots \\ 0 \end{bmatrix}\)
Comencemos el código de Python para resolver este problema. Lo más importante a destacar en él es la conformación de las matrices y vectores utilizando la biblioteca numpy.
Creación de la matriz A que contiene los coeficientes de cada ecuación que describe el problema:
def Creating_Matrix_A(Nx, Ny, r):
# Diagonal principal
diag0 = np.tile(np.full(Nx, 1 - 4 * r), Nx)
# Diagonal principal superior
diag1 = np.tile(np.concatenate((np.array([0.0, 2 * r]), np.full(Nx - 2, r))), Nx)
# Diagonal principal inferior
diag_1 = np.flip(diag1)
# Diagonal superior
diag_sup = np.concatenate(
(np.zeros(Nx), np.full(Nx, 2 * r), np.tile(np.full(Nx, r), Nx - 2))
)
# Diagonal inferior
diag_inf = np.flip(diag_sup)
# Retornando Matriz sparse
return spdiags(
[diag_inf, diag_1, diag0, diag1, diag_sup],
[-Nx, -1, 0, 1, Nx],
Nx**2,
Ny**2,
).tocsr()
Visualicémosla a un nivel pequeño de \(5X5\) con la ayuda de la biblioteca Sympy.
A = Creating_Matrix_A(3, 3, 0.5)
# Imprimiendo matriz de prueba A con Sympy
Ap = sy.Matrix(A.todense())
Ap
Vamos la estructura que tiene la matriz A ploteandola con la función spy del módulo matplotlib.
plt.spy(A, markersize=2)
plt.title("Estructura de la matriz A")
plt.show()
Creemos la matriz \(R\) que contiene parte de las condiciones de frontera de Neumann no homogéneas que definen el flujo entrante de agua por la parte superior del dominio:
def creating_matrix_R(Nx, Ny, dx, r, D):
# Crear vector completo de ceros
R = np.zeros(Nx * Ny)
# Sustituir a partir del segundo bloque hasta el penúltimo, el último
# elemento con el valor del flujo de las condiciones de fronteras
# de Nuemann.
R[2 * Nx - 1 : Nx * Ny - 1 : Nx] = -2.0 * r * dx * D
return spdiags([R], [0], Nx**2, Ny**2)
Con el uso de Sympy podemos visualizarlos en este ejemplo reducido
R = creating_matrix_R(3, 3, 0.1, 0.5, 0.2)
sy.Matrix(R.todense())
Si observamos la estructura de esta matriz veremos que solo tiene valores distintos de cero en su diagonal y muy esparcidos.
plt.spy(R, markersize=2)
plt.title("Estructura de la matriz R")
plt.show()
La estructura de la matriz \((A + R)\) sigue siendo la misma pero con la adición de las valores de \(R\) en los lugares correspondientes de la diagonal.
sy.Matrix((A + R).todense())
Como parte del flujo definido en la parte superior del dominio se tiene también estos valores que no son coeficientes de las variables involucradas. Precisamente representa la cantidad de líquido que se está aportando al sistema en el tiempo (\(g\)).
def creating_vector_b(Nx, Ny, dx, r, D, g):
# Crear vector completo de ceros
b = np.zeros(Nx * Ny)
# Sustituir a partir del segundo bloque hasta el penúltimo, el último
# elemento con el valor del flujo de las condiciones de fronteras
# de Nuemann.
b[2 * Nx - 1 : Nx * Ny - 1 : Nx] += 2.0 * r * dx * D * g
return b
Igualmente se puede visualizar con el módulo Sympy. Esta vez es un vector.
b = creating_vector_b(3, 3, 0.1, 0.5, 0.2, np.full(1, 2))
sy.Matrix(b)
Ahora realicemos el ejemplo con dimensiones más grandes y veamos que sucede. El flujo de entrada está diseñado para que sea constante durante \(0.3\) minutos y luego nulo. Veamos que es lo que sucede.
folder_name = "Infiltration"
try:
os.makedirs(folder_name)
except FileExistsError:
pass
def gfun(t, x):
if t < 1.0:
return np.concatenate(
(np.zeros(Nx // 2 - 4), np.full(6, 1e-4), np.zeros(Nx // 2 - 4))
)
else:
return np.zeros(Nx - 2)
# Coeficiente de almacenamiento [-]
S = 5e-5
# Espesor [m]
mu = 1.0
# Conductividad Hidráulica [m/day] --> [m/s]
K = 1e-1 / (24 * 3600)
# infiltración del flujo de agua en la superficie [m/s]
fg = 1e-4
# Coeficiente de difusión
D = K * mu / S
r = 0.2
dx = 0.1
dy = 0.1
Nx = 50
Ny = 50
dx = 0.1
dy = 0.1
x = np.arange(0, Nx)
y = np.arange(0, Ny)
X, Y = np.meshgrid(x, y)
g = gfun(0.0, x)
u_n = np.zeros((Nx, Ny)).flatten()
dt = r * dx**2 / D # CFL - Condition
t = 0.0
T = 8000
A = Creating_Matrix_A(Nx, Ny, r)
R = creating_matrix_R(Nx, Ny, dx, r, D)
b = creating_vector_b(Nx, Ny, dx, r, D, g)
for k in range(1, T):
t += dt
g = gfun(t, x)
b = creating_vector_b(Nx, Ny, dx, r, D, g)
u_n = (A + R) * u_n + b
Z = u_n.reshape((Nx, Ny))
if k % 100 == 0:
cm_size = 1 / 2.54
fig = plt.figure(
tight_layout=True,
figsize=(40 * cm_size, 23 * cm_size),
)
ax = fig.add_subplot(1, 1, 1, projection="3d")
surf = ax.plot_surface(
X, Y, Z, cmap=cm.gist_earth, linewidth=0, antialiased=False, alpha=0.5
)
ax.view_init(75, 230)
# plt.draw()
ax.grid()
ax.set_xlabel("prof")
ax.set_ylabel("x")
ax.set_zlim3d([1e-10, 4e-8])
ax.set_title(
"Infiltración de agua en grava (2D)\nt={} min, D={} $m^2/s$, dx={} $m$, dt={} $s$\n"
r"S={} [-], K={} $m/s$, g={} $m/s$, $\mu=${} m".format(
np.round(t / 60, 2),
np.format_float_scientific(D, 3),
dx,
np.round(dt, 2),
np.format_float_scientific(S, 2),
np.format_float_scientific(K, 2),
np.format_float_scientific(fg, 2),
mu,
)
)
plt.savefig("Infiltration/time_%05d.png" % k)
plt.close()
# print("time =", t)
Ejercicios de la clase#
Ejercicio #1: Calculando función en 3D.#
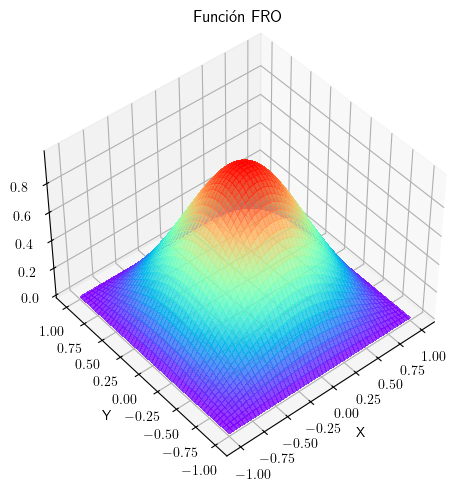
En este ejercicio usted deberá de implementar el método fro el cual se encuentra en blanco debajo. Este método calcula la función \(\text{fro}\) en el dominio \(x, y \in [-1, 1]\times[-1, 1]\) tal que
\(fro(x, y) = \frac{\left|\left(x^2 - 1\right)\left(y^2 - 1\right)\right|}{x^2 + y^2 + 1}\).
Pasos para la resolución del ejercicio:
Crear una rejilla que discretize el dominio \([-1, 1]\times[-1, 1]\).
Implementar la función en el método
fro.Vectorizar el método
froy calcular los valores para cada elemento de la rejilla (matrizZ).Utilizar el método llamado
ploteaproporcionado para mostrar el resultado.
¡El método plotea ya está hecho! No tiene que modificar nada en él.
def plotea(X, Y, Z):
fig = plt.figure(tight_layout=True)
ax = fig.add_subplot(1, 1, 1, projection="3d")
surf = ax.plot_surface(
X, Y, Z, cmap=cm.rainbow, linewidth=0, antialiased=False, alpha=0.8
)
ax.view_init(45, 230)
# plt.draw()
ax.grid()
ax.set_xlabel("X")
ax.set_ylabel("Y")
# ax.set_zlim3d([1e-10, 4e-8])
ax.set_title("Función FRO")
plt.show()
plt.close()
Función fro que deberá de implementar
def fro(X, Y):
return np.abs((X**2 - 1) * (Y**2 - 1)) / (1 + X**2 + Y**2)
pass
Código principal del ejercicio. Solo tiene que seguir las instrucciones de los comentarios.
# Crear una rejilla. Nota: usar la función ```np.meshgrid``` para ello.
x = np.linspace(-1, 1, 100)
y = np.linspace(-1, 1, 100)
X, Y = np.meshgrid(x, y)
# Obtener una versión vectorizada de la función ```fro```.
fro = np.vectorize(fro)
# Calcular la matriz Z evaluando la rejilla en la función ```fro```.
Z = fro(X, Y)
# Ejecutar la función ```plotea``` con la rejilla y la matriz Z
plotea(X, Y, Z)
Ejercicio #2:#
Implemente los métodos create_A y create_B_hat correspondientes a la implementación del método de Crank Nicolson para la resolución del problema de Poison con condiciones de frontera de Dirichlet homogéneas y las condiciones iniciales que se especifican a continuación.
El problema se define de la siguiente manera:
Sean \(x, y \in \bar{\Omega}([-1, 1]\times[-1, 1])\) y \(t \in [0, T)\) tales que se cumple
\(\dfrac{\partial u}{\partial t} - D \Delta u = 0\)
\(u(t=0, x, y) = \frac{\left|\left(x^2 - 1\right)\left(y^2 - 1\right)\right|}{x^2 + y^2 + 1},\, ∀ x, y \in \Omega\)
\(u(t > 0, x, y) = 0, \, ∀ x, y \in \partial \Omega\)
El método de Crank Nicolson es un método implícito en el cual se utiliza un parámetro \(\Theta = 1/2\) que describe una regla de los trapecios en el tiempo para realizar una integración temporal de segundo orden. En el caso del espacio también utiliza un esquema de diferencias centradas que es de segundo orden. Este método a diferencia del anterior es incondicionalmente estable por lo que es adecuado para problemas grandes o de larga simulación temporal porque brinda más posibilidades de escoger un \(dt\) más grande.
La forma matricial de este método pudiera definirse de la siguiente forma:
\(u^{n+1} = A^{-1} (\hat{B} \, u^n)\)
Al ser \(A_{Nx\times Ny}\) y \(\hat{B}_{Nx\times Ny}\) matrices sparse se utiliza la función scipy.sparse.linalg.spsolve. El vector \(u^n\) continua siendo el mismo descrito en el ejemplo #1 de la clase.
Las matrices se definen de la siguiente manera
\(A= \begin{bmatrix} L & -\frac{r}{2} I & & \\ -\frac{r}{2} I & L & -\frac{r}{2} I & \\ & \ddots & \ddots & \ddots \\ & & -\frac{r}{2} I & L & -\frac{r}{2} I\\ & & & -\frac{r}{2} I & L \end{bmatrix}\)
y
\(\hat{B}= \begin{bmatrix} Q & \frac{r}{2} I & & \\ \frac{r}{2} I & Q & \frac{r}{2} I & \\ & \ddots & \ddots & \ddots \\ & & \frac{r}{2} I & Q & \frac{r}{2} I\\ & & & \frac{r}{2} I & Q \end{bmatrix}\),
donde
\(L = \begin{bmatrix} 1 + 2r & -\frac{r}{2} & & &\\ -\frac{r}{2} & 1 + 2r & -\frac{r}{2} & &\\ & \ddots & \ddots & \ddots &\\ & & -\frac{r}{2} & 1 + 2r & -\frac{r}{2}\\ & & & -\frac{r}{2} & 1+2r \end{bmatrix}\)
\(Q = \begin{bmatrix} 1 - 2r & \frac{r}{2} & & &\\ \frac{r}{2} & 1 - 2r & \frac{r}{2} & &\\ & \ddots & \ddots & \ddots &\\ & & \frac{r}{2} & 1 - 2r & \frac{r}{2}\\ & & & \frac{r}{2} & 1-2r \end{bmatrix}\)
El código que verá a continuación ya está pre-hecho. Solo usted deberá de escribir el código que genere las matrices \(A\) y \(\hat{B}\).
Creando la matriz \(A\):
def create_A(r, N):
diag_0 = np.full((N * N), 1.0 + 2.0 * r)
diag1 = np.tile(np.concatenate((np.array([0.0]), np.full(N - 1, -r / 2.0))), N)
diag_1 = np.tile(np.concatenate((np.full(N - 1, -r / 2.0), np.array([0.0]))), N)
diag_N = np.full((N * N), -1 * r / 2.0)
return spdiags(
[diag_N, diag_1, diag_0, diag1, diag_N], [-N, -1, 0, 1, N], N**2, N**2
).tocsr()
A = sy.Matrix(create_A(0.5, 5).todense())
A
Creando la matriz \(\hat{B}\):
def create_B_hat(r, N):
diag_0 = np.full((N * N), 1.0 - 2.0 * r)
diag1 = np.tile(np.concatenate((np.array([0.0]), np.full((N - 1,), r / 2.0))), N)
diag_1 = np.tile(np.concatenate((np.full((N - 1,), r / 2.0), np.array([0.0]))), N)
diag_N = np.full((N * N), r / 2.0)
return spdiags(
[diag_N, diag_1, diag_0, diag1, diag_N], [-N, -1, 0, 1, N], N**2, N**2
).tocsr()
B_hat = sy.Matrix(create_B_hat(0.5, 5).todense())
B_hat
Función \(u(x, y) = \frac{\left|\left(x^2 - 1\right)\left(y^2 - 1\right)\right|}{x^2 + y^2 + 1}\) utilizada para inicializar el dominio en el \(t=0\).
def fro(X, Y):
return np.abs((X**2 - 1) * (Y**2 - 1)) / (1 + X**2 + Y**2)
Código principal del ejercicio. El único cambio que usted debe realizar es la dirección en donde desea salvar los png resultantes.
Solo tiene que poner la dirección correcta y completa de la carpeta local en su computadora, como un string en la variable
# Modificar la dirección de salva !!!
folder_name = "PeC3"
try:
os.makedirs(folder_name)
except FileExistsError:
pass
# Vectorizando la función de mcondiciones iniciales
fro = np.vectorize(fro)
# Discretización del dominio
dx = dy = 1 / 5.0
x = np.arange(-1, 1 + dx, dx)
y = np.arange(-1, 1 + dx, dy)
Nx = x.shape[0]
Ny = y.shape[0]
XX, YY = np.meshgrid(x, y)
# Coeficiente de estabilización (CFL)
r = 0.25
# Coeficiente de difusión
D = 1e-3
# Calculando dt
dt = r * dx**2 / D
# Tiempo inicial
t = 0.0
# Tiempo total
T = 77
# Inicialización de variable para condiciones iniciales.
# Las fronteras serán iguales a cero
u = np.zeros((Nx, Ny))
# Aplicar función de condiciones iniciales a u
u = fro(XX, YY) * 200.0
# Crear matriz A
A = create_A(r, u.shape[0] - 2)
# Crear matriz B sombrero
B_hat = create_B_hat(r, u.shape[0] - 2)
# Ciclo principal
for k in range(1, T):
# Convertir u de 2D a 1D usando función aplanar (flatten)
u_flat = u[1:-1, 1:-1].flatten()
# Creando vector de carga (load vector en inglés)
b = B_hat * u_flat
# Resolución del sistema de ecuaciones para matrices sparse.
# Se obtiene la nueva solución en el timepo t + dt * k
u_flat = spsolve(A, b)
# Convertir u de 1D a 2D nuevamente
u[1:-1, 1:-1] = u_flat.reshape((u.shape[0] - 2, u.shape[1] - 2))
# Avanzar en el tiempo
t += k * dt
# Plotear solución y salvarla como png
fig = plt.figure()
ax = fig.add_subplot(111)
cb = ax.contourf(
XX, YY, u, cmap=cm.jet, levels=np.linspace(0, 200 + dt, 50), alpha=0.5
)
ax.set_xticks(x)
ax.set_yticks(y)
ax.set_xlim([-1.1, 1.1])
ax.set_ylim([-1.1, 1.1])
ax.set_xlabel("X")
ax.set_ylabel("Y")
plt.colorbar(cb)
plt.grid()
plt.title("t%f" % t)
plt.savefig("%s/time_%05d.png" % (folder_name, k))
plt.close()